

概要
前回、Google CloudのDocument AIを使用してテキストを抽出しましたが、今回はより具体的な例として、請求書の内容をテキスト抽出してみようと思います。
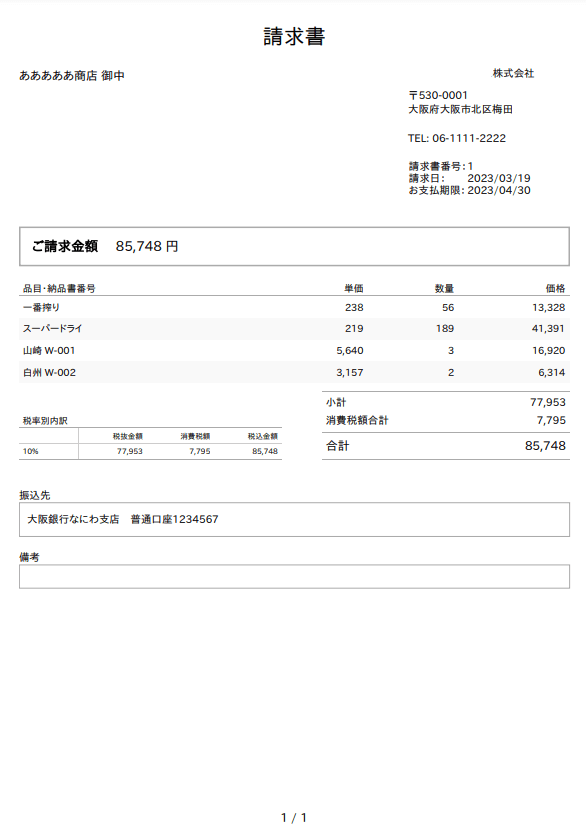
請求書のサンプルとして「Money Forward Cloud請求書」で作成した下記のPDFの請求書を用意しました。
準備
プロセッサの選定
さて、数あるプロセッサの内どれを使うか選定していきましょう。
ガイドを確認すると、ほとんどのプロセッサは日本語に対応できていないようです。
Full processor and detail list
https://cloud.google.com/document-ai/docs/processors-list
下記のサイトでいくつかのプロセッサが無料で簡単に試せますので、試してみました。
Google Cloud Document AI Try It!
https://cloud.google.com/document-ai/docs/drag-and-drop
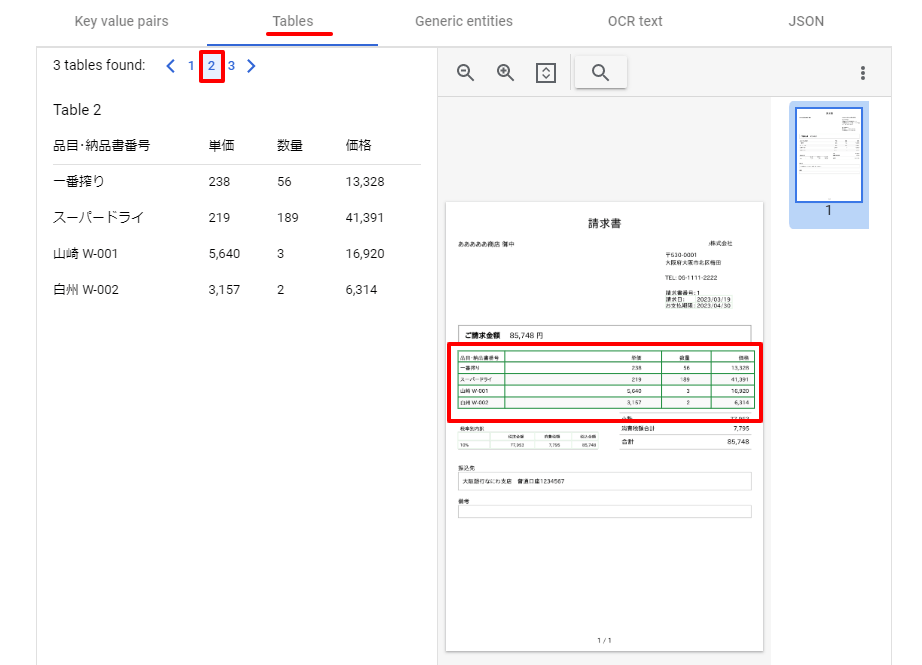
すると、Form Parserがいい感じです。
テーブルは全部で3つ認識していて、2つめのテーブルが明細部をバッチリと認識してくれています。
明細部の右下の合計欄がテーブルとして認識されていないことが少し残念ですが、値は、Key Value pairsで取得できそうです。
今回はこのForm Parserを使用していく事にします。
その他の初期設定
Document AIの設定、APIリスエストの認証、Pythonの設定は前回の下記の記事を参照ください。
プログラム
下記のページを参考にしてすすめていきます。
Process a document using a Form Parser processor
https://cloud.google.com/document-ai/docs/samples/documentai-process-form-document
注意点
1点注意があります。ドキュメントを読むとForm Parserは日本語に対応していないようです。(2023年3月時点)
ではなぜデモサイト(Try It)で試した時はでは日本語を取得できたのでしょう?
さらにドキュメントを見てみると、プロセッサーのバージョン2.0において、200以上の言語がサポートされたようです。どうもこの中に日本語が含まれているのでしょう。
今回はこの2.0バージョンを使用しますが、現時点でバージョン2.0はStable(安定版)ではなくリリース候補版ということを認識しておく必要があります。(2023年3月時点)
プログラム
前回のプログラムをベースに下記のプログラムを作成してテストしました。
Document AIではAPIのエンドポイントにアクセスすると、デフォルトで設定されているバージョン1.0が使用されますので、今回は、processor_version_pathを使用して、バージョンを指定できるように変更しました。(管理コンソールからデフォルトのバージョンを2.0に変更してもオッケーです。)
from typing import Sequence
from google.cloud import documentai_v1 as documentai
def process_document(project_id: str, location: str,
processor_id: str, processor_version_id: str, file_path: str,
mime_type: str) -> documentai.Document:
"""
Processes a document using the Document AI API.
"""
# Instantiates a client
documentai_client = documentai.DocumentProcessorServiceClient()
# The full resource name of the processor version
# e.g. projects/{project_id}/locations/{location}/processors/{processor_id}/processorVersions/{processor_version_id}
resource_name = documentai_client.processor_version_path(
project_id, location, processor_id, processor_version_id
)
# Read the file into memory
with open(file_path, "rb") as image:
image_content = image.read()
# Load Binary Data into Document AI RawDocument Object
raw_document = documentai.RawDocument(
content=image_content, mime_type=mime_type)
# Configure the process request
request = documentai.ProcessRequest(
name=resource_name, raw_document=raw_document)
# Use the Document AI client to process the sample form
result = documentai_client.process_document(request=request)
return result.document
def main():
"""
Run the codelab.
"""
project_id = 'YOUR_PROJECT_ID'
location = 'YOUR_PROCESSOR_LOCATION' # Format is 'us' or 'eu'
processor_id = 'YOUR_PROCESSOR_ID' # Create processor in Cloud Console
processor_version_id = 'YOUR_PROCESSOR_VERSION_ID' # Processor version to use
file_path = 'invoice.pdf' # The local file in your current working directory
# Refer to https://cloud.google.com/document-ai/docs/processors-list for the supported file types
mime_type = 'application/pdf'
document = process_document(project_id=project_id, location=location,
processor_id=processor_id, processor_version_id=processor_version_id, file_path=file_path,
mime_type=mime_type)
print("Document processing complete.")
#print(f"Text: {document.text}")
# Read the form fields and tables output from the processor
text = document.text
for page in document.pages:
print(f"\n\n**** Page {page.page_number} ****")
print(f"\nFound {len(page.tables)} table(s):")
for table in page.tables:
num_collumns = len(table.header_rows[0].cells)
num_rows = len(table.body_rows)
print(f"Table with {num_collumns} columns and {num_rows} rows:")
# Print header rows
print("Columns:")
print_table_rows(table.header_rows, text)
# Print body rows
print("Table body data:")
print_table_rows(table.body_rows, text)
print(f"\nFound {len(page.form_fields)} form field(s):")
for field in page.form_fields:
name = layout_to_text(field.field_name, text)
value = layout_to_text(field.field_value, text)
print(f" * {repr(name.strip())}: {repr(value.strip())}")
def print_table_rows(
table_rows: Sequence[documentai.Document.Page.Table.TableRow], text: str
) -> None:
for table_row in table_rows:
row_text = ""
for cell in table_row.cells:
cell_text = layout_to_text(cell.layout, text)
row_text += f"{repr(cell_text.strip())} | "
print(row_text)
def layout_to_text(layout: documentai.Document.Page.Layout, text: str) -> str:
"""
Document AI identifies text in different parts of the document by their
offsets in the entirety of the document's text. This function converts
offsets to a string.
"""
response = ""
# If a text segment spans several lines, it will
# be stored in different text segments.
for segment in layout.text_anchor.text_segments:
start_index = int(segment.start_index)
end_index = int(segment.end_index)
response += text[start_index:end_index]
return response
if __name__ == "__main__":
main()
プログラムを実行すると、下記のようにいい感じでテキストが取得できております。
”郵便番号のマーク”や、”抜金額”、”稅”など、若干気になるところはありますが、その他はほぼ取得できているので上出来でしょう。
“振込先”や”備考”がここにはなかったのですが、OCRのテキストとしてはきちんと取得できておりますので、問題なしとします。
**** Page 1 ****
Found 3 table(s):
Table with 4 columns and 1 rows:
Columns:
'' | '税抜金額' | '消費稅額' | '税込金額' |
Table body data:
'10%' | '77,953' | '7,795' | '85,748' |
Table with 4 columns and 4 rows:
Columns:
'品目・納品書番号' | '単価' | '数量' | '価格' |
Table body data:
'一番搾り' | '238' | '56' | '13,328' |
'スーパードライ' | '219' | '189' | '41,391' |
'山崎 W-001' | '5,640' | '3' | '16,920' |
'白州 W-002' | '3,157' | '2' | '6,314' |
Table with 2 columns and 1 rows:
Columns:
'請求日:' | '2023/03/19' |
Table body data:
'お支払期限:' | '2023/04/30' |
Found 16 form field(s):
* 'ご請求金額': '85,748円'
* 'お支払期限:': '2023/04/30'
* '請求日:': '2023/03/19'
* '請求書番号:': '1'
* '合計': '85,748'
* '消費稅額': '抜金額\n税込金額\n77,953\n7,795\n85,748'
* 'TEL:': '06-1111-2222'
* '小計\n消費税額合計': '77,953\n7,795\n合計\n85,748'
* '税抜金額': '77,953'
* '税込金額': '85,748'
* '品目・納品書番号': '一番搾り'
* '山崎 W-001': '5,640\n3\n16,920'
* 'T530-0001': '大阪府大阪市北区梅田'
* '株式会社': 'T530-0001'
* '白州 W-002': '3,157\n2\n6,314'
* '口座1234567': ''
最後に
今回は、日本語が対応しているForm Parserを使用しましたが、トレーニング可能なInvoice Parserが日本語対応されるとさらに精度が上がると思われるので、期待したいと思います。
お察しの通り、私がお酒が好きなことは紛れもない事実です。