

概要
今回は、Google CloudのDocument AIを使用して、PDFファイルのテキストをAI OCRで文字認識してテキストを抽出してみます。
一部手順を変えておりますが、下記のサイトを参考に進めていきます。
Document AI と Python による光学式文字認識(OCR)
https://codelabs.developers.google.com/codelabs/docai-ocr-python?hl=ja
Document AIの設定
Cloud Document AI APIの有効化
DocumentAIのAPIを使用できるように設定します。
検索欄からCloud Document AI APIを検索して、有効にするを選択します。

プロセッサの作成
OCRプロセッサを作成します。
[Document AI]メニューの[プロセッサギャラリー]メニューから、プロセッサを確認を選択します。
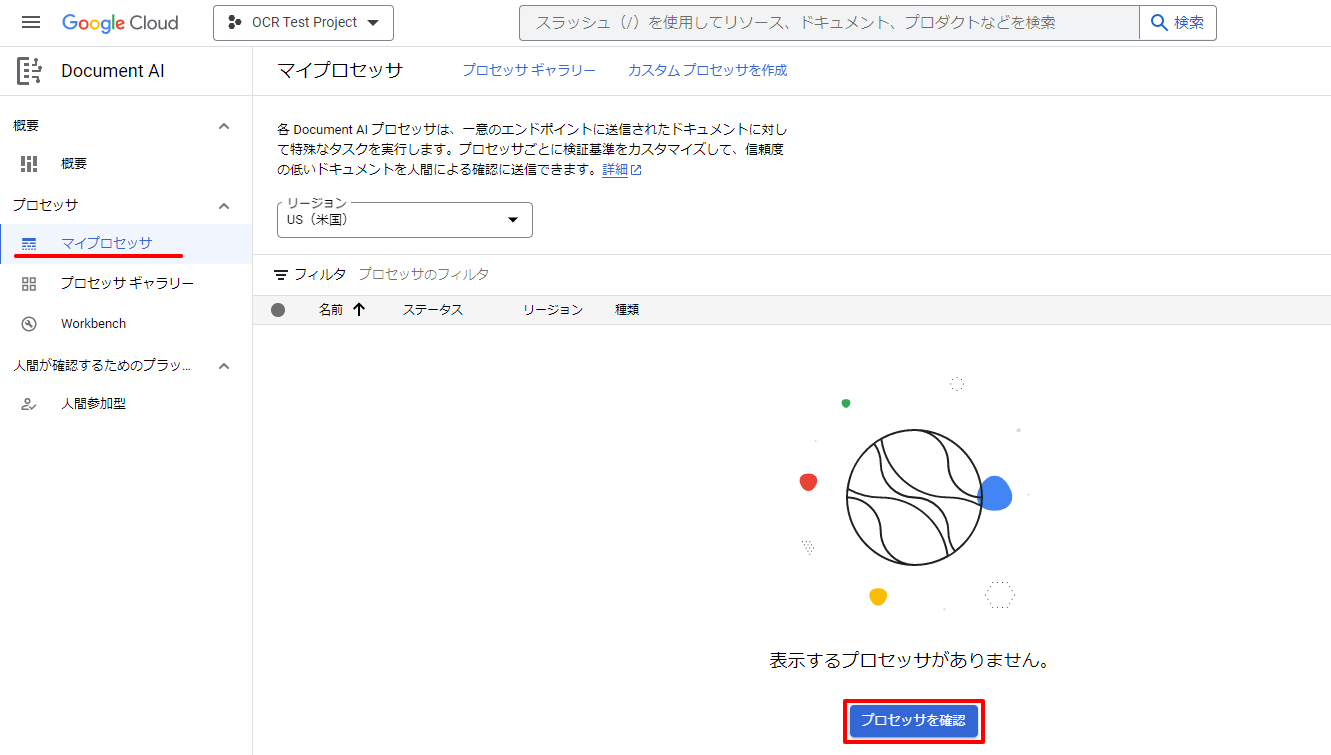
”Document OCR”項目のプロセッサを作成しますを選択します。
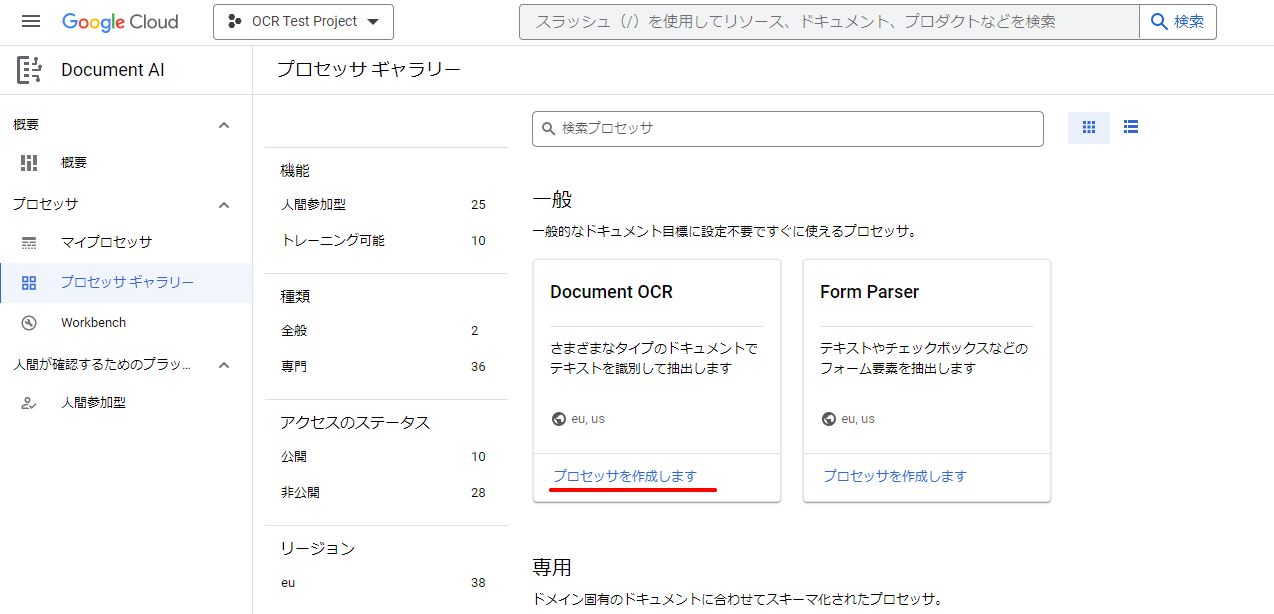
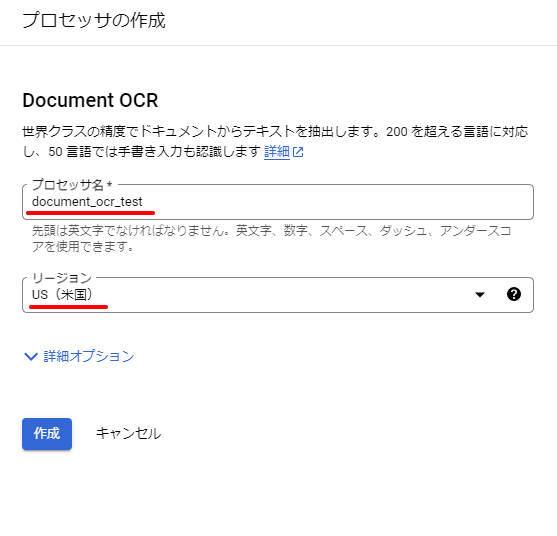
今回は下記のように入力しました。プロセッサ名:document_ocr_testリージョン:US(米国)
APIリクエストの認証
サービスアカウントの作成
Google CloudのAPIにリクエストを行うには、いくつか方法があるのですが、今回はサービスアカウントを作成する方法で進めます。
サービスアカウントはプロジェクトに属するもので、PythonクライアントライブラリでAPIリクエストを行うために使用されます。
メニュー[IAMと管理]-[サービスとアカウント]から、サービスアカウントを作成を選択します。
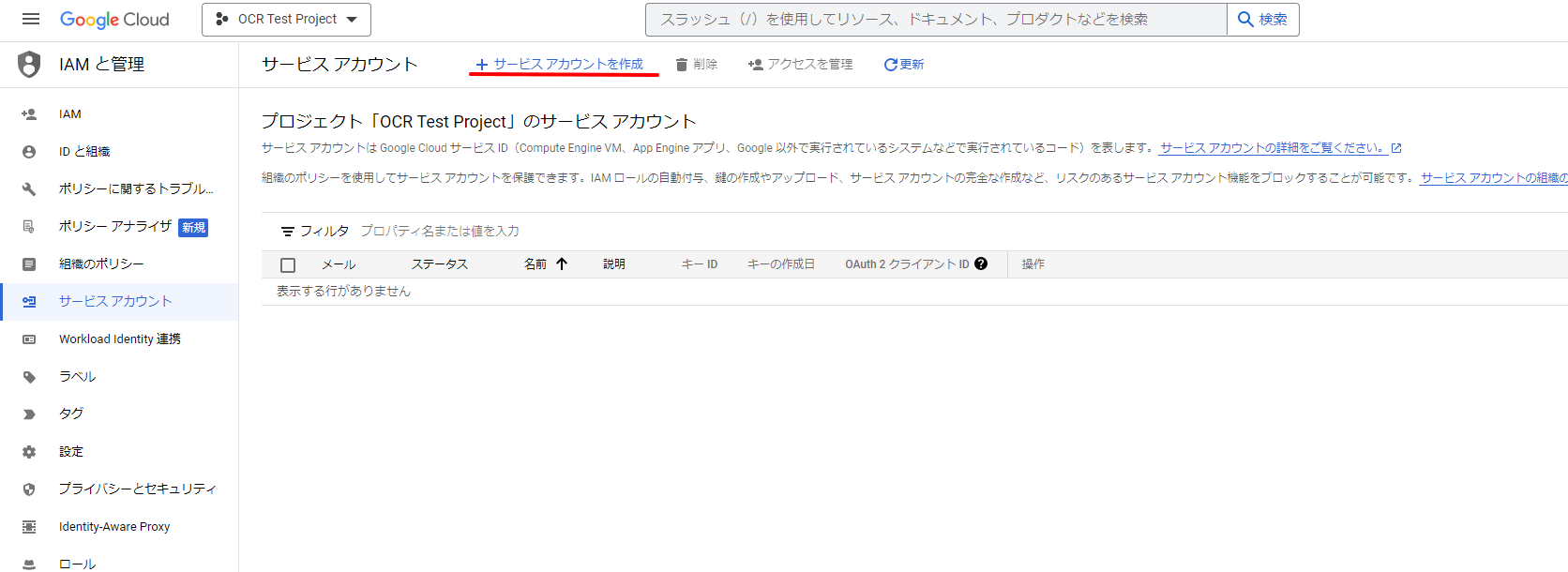
今回は、下記のように入力しました。サービスアカウント名:ocr-api-accessサービスアカウントID:ocr-api-access
メールアドレスは後で使用しますのでコピーしておきます。
アクセス許可関連は後ほど設定しますので、何も入力せずに、完了を選択します。
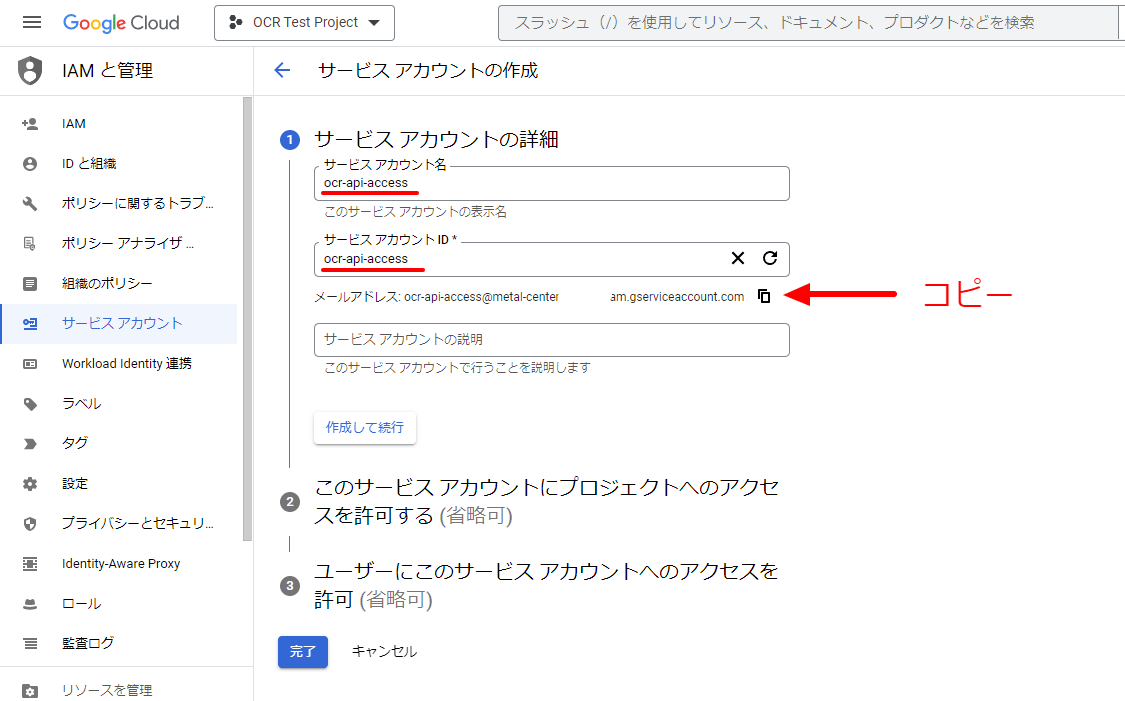
続いてAPI認証する為のキーを作成します。
作成されたサービスアカウントを選択して、キータブから鍵を追加をクリックして、新しい鍵を作成を選択します。
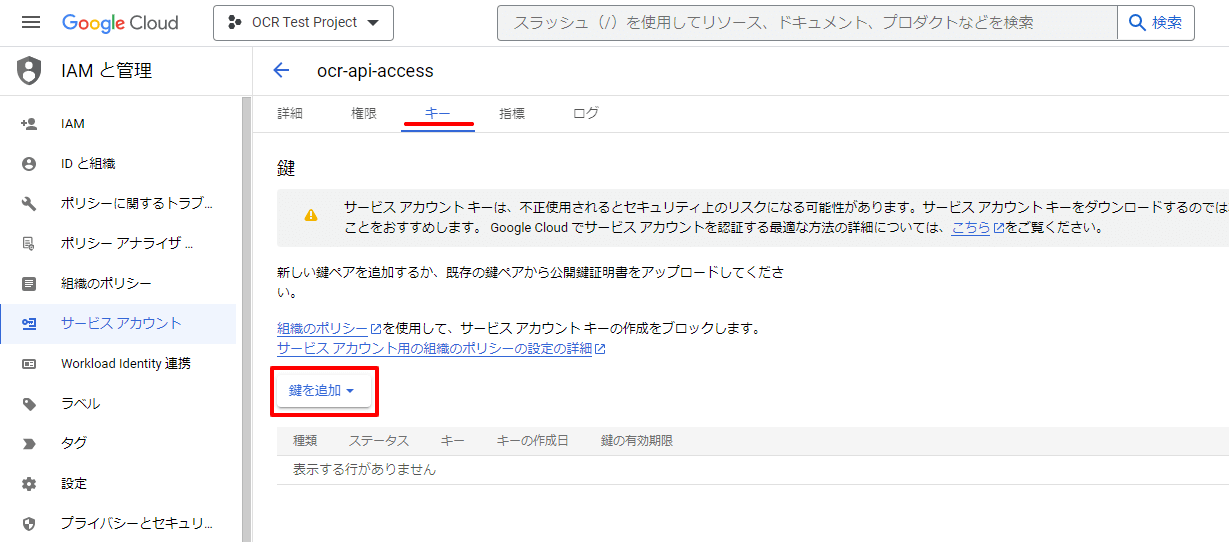
JSONを選択して作成されたファイルをダウンロードします。

ロールの作成
サービスアカウントに割り当てるロールを作成します。
タイトル:role-document-ai-api
と入力して、権限を追加を選択します。

“Document AI API ユーザー”を検索して、全ての権限にチェックを付けて、ロールの登録を完了します。
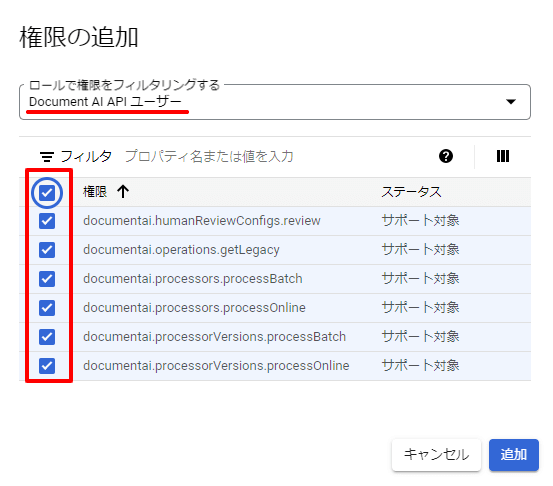
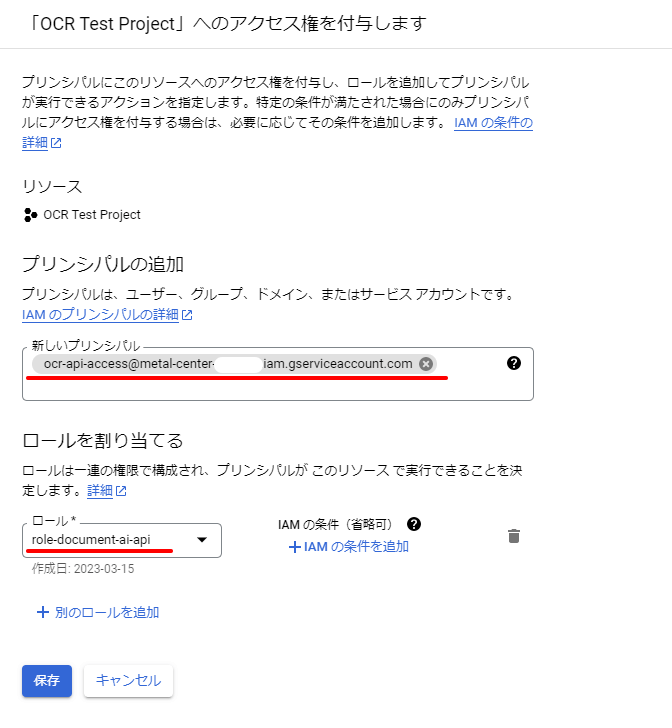
サービスアカウントにロールを付与
サービスアカウントに先ほど作成したロールを付与します。
[IAM]メニューより、アクセス権を付与を選択します。
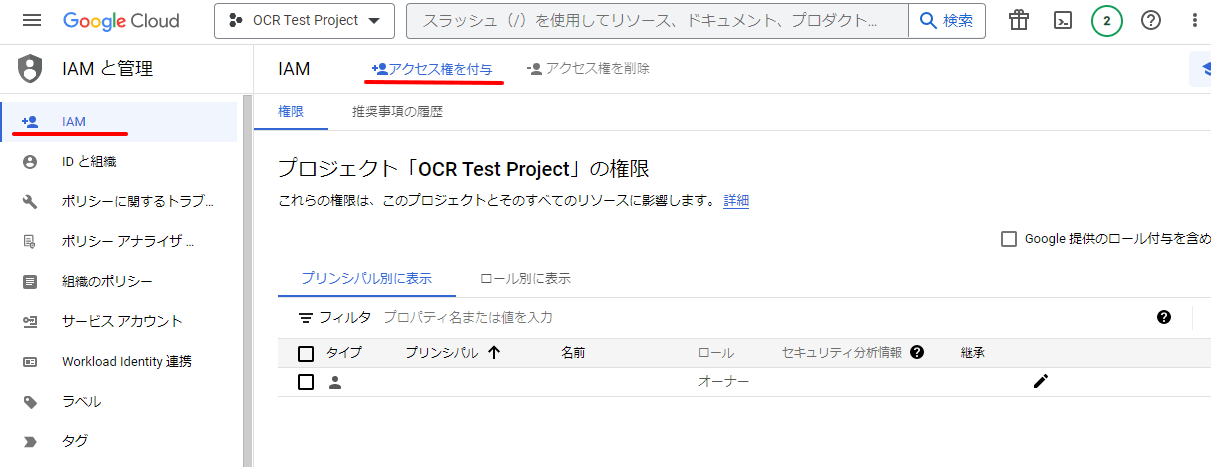
新しいプリンシパル:先ほどコピーしたサービスアカウントのメールアドレスロール:作成済のロール”role-document-ai-api”
を入力して保存します。
pythonの設定
クライアントライブラリのインストール
クライアントライブラリをインストールします。
# document AIのクライアントライブラリをインストール
pip3 install --upgrade google-cloud-documentai
環境変数にダウンロードしたjsonファイルのパスを登録します。
(windowsコマンドプロンプトの時はsetコマンド)
環境変数を使用して認証情報を提供する
https://cloud.google.com/docs/authentication/production?hl=ja#linux-or-macos
# 環境変数に登録
# KEY_PATHの部分はファイルパスを指定します。
export export GOOGLE_APPLICATION_CREDENTIALS="KEY_PATH"
サンプルPDFのダウンロード
下記のリンクからサンプルのPDFをダウンロードします。
プログラム
今回は下記のプログラムを使用しました。
環境により下記の部分を書き換えます。
YOUR_PROJECT_ID:プロジェクトIDYOUR_PROJECT_LOCATION:リージョン(‘us’ or ‘eu’)YOUR_PROCESSOR_ID:プロセッサーID
from google.cloud import documentai_v1 as documentai
def process_document(project_id: str, location: str,
processor_id: str, file_path: str,
mime_type: str) -> documentai.Document:
"""
Processes a document using the Document AI API.
"""
# Instantiates a client
documentai_client = documentai.DocumentProcessorServiceClient()
# The full resource name of the processor, e.g.:
# projects/project-id/locations/location/processor/processor-id
# You must create new processors in the Cloud Console first
resource_name = documentai_client.processor_path(
project_id, location, processor_id)
# Read the file into memory
with open(file_path, "rb") as image:
image_content = image.read()
# Load Binary Data into Document AI RawDocument Object
raw_document = documentai.RawDocument(
content=image_content, mime_type=mime_type)
# Configure the process request
request = documentai.ProcessRequest(
name=resource_name, raw_document=raw_document)
# Use the Document AI client to process the sample form
result = documentai_client.process_document(request=request)
return result.document
def main():
"""
Run the codelab.
"""
project_id = 'YOUR_PROJECT_ID'
location = 'YOUR_PROJECT_LOCATION' # Format is 'us' or 'eu'
processor_id = 'YOUR_PROCESSOR_ID' # Create processor in Cloud Console
file_path = 'Winnie_the_Pooh_3_Pages.pdf' # The local file in your current working directory
# Refer to https://cloud.google.com/document-ai/docs/processors-list for the supported file types
mime_type = 'application/pdf'
document = process_document(project_id=project_id, location=location,
processor_id=processor_id, file_path=file_path,
mime_type=mime_type)
print("Document processing complete.")
print(f"Text: {document.text}")
if __name__ == "__main__":
main()
実行
準備は整ったので、実際にプログラムを動かしてみましょう。
下記のテキストが抽出されました。
PDFを見てみるとわかるのですが、下線や汚れ等のノイズやフォントの大きさや違いなどが存在しますが、上手く文字認識ができております。
Text: IN WHICH We Are Introduced to
CHAPTER I
Winnie-the-Pooh and Some
Bees, and the Stories Begin
HERE is Edward Bear, coming
downstairs now, bump, bump, bump, on the back
of his head, behind Christopher Robin. It is, as far
as he knows, the only way of coming downstairs,
but sometimes he feels that there really is another
way, if only he could stop bumping for a moment
and think of it. And then he feels that perhaps there
isn't. Anyhow, here he is at the bottom, and ready
to be introduced to you. Winnie-the-Pooh.
When I first heard his name, I said, just as you
are going to say, "But I thought he was a boy?"
"So did I," said Christopher Robin.
"Then you can't call him Winnie?"
"I don't."
"But you said--"
"He's Winnie-ther-Pooh. Don't you know what
'ther' means?”
I
Digitized by
Google
WINNIE-THE-POOH
“Ah, yes, now I do," I said quickly; and I hope
you do too, because it is all the explanation you are
going to get.
Sometimes Winnie-the-Pooh likes a game of some
sort when he comes downstairs, and sometimes he
likes to sit quietly in front of the fire and listen to a
story. This evening-
"What about a story?" said Christopher Robin.
"What about a story?" I said.
"Could you very sweetly tell Winnie-the-Pooh
one?"
"I suppose I could," I said. "What sort of stories
does he like?"
"About himself. Because he's that sort of Bear."
"Oh, I see."
"So could you very sweetly?"
"I'll try," I said.
So I tried,
Once upon a time, a very long time ago now,
about last Friday, Winnie-the-Pooh lived in a forest
all by himself under the name of Sande.s.
("What does 'under the name' mean?" asked
Christopher Robin.
"It means he had the name over the door in gold
letters, and lived under it.”
Digitized by
Google
WE ARE INTRODUCED
AB SANDER
RNIG
AALSO
"Winnie-the-Pooh wasn't quite sure," said Chris-
topher Robin.
"Now I am," said a growly voice.
"Then I will go on," said I.)
3
One day when he was out walking, he came to
an open place in the middle of the forest, and in the
middle of this place was a large oak-tree, and, from
the top of the tree, there came a loud buzzing-noise.
Winnie-the-Pooh sat down at the foot of the tree,
put his head between his paws and began to think.
Digitized by
Google
最後に
今回使用した、process_documentメソッドは送信できるページ数とファイルサイズに制限があり、1 回の API 呼び出しで 1 つのドキュメント ファイルしか使用できないようです。
ですので、大きいファイルや複数ファイルを扱うときは、batch_process_documentsを使用すればよいようです。